Bridge & Tunnel Data 4 Ways
Here we look at a few different ways to store the MTA Bridge and Tunnel Hourly Traffic Dataset for further analysis.
The goal of this post a bit more exposition on the how and why around each of these methods, with less focus on getting a proper environment set up for each solution. With that said, I’ll try to leave a few hints for getting things working where I can.
I’ll move from “simpler” solutions to slightly more “complex” setups, but for someone reading this trying to decide which is a good fit for your data pipeline, I would stop once you hit a solution that seems to meet your general needs. That said I think it would be worth reading until the end, especially if you haven’t checked out Apache Iceberg yet.
Storage Solution 0: Don’t
This solution is a bit of a cheating one, but it’s worth pointing out: Why do you need to actually store this data yourself anyway?
For the sake of this post, I’ll assume you understand your data needs well enough to know whether storing the dataset yourself is the right move. Specifically, if you plan to do any downstream transformation to your data, storing the output from the API is a good practice that can help speed up incremental processing or reruns.
Storage Solution 1: Local JSON
With Solution 0 out of the way, the simplest way to store this dataset might be to stick the data on your local filesystem, provided the compute you’re using has one.
Below is the code to grab the dataset, and stick it into a local JSON file. There’s quite a lot of records (>2M at the time of writing) so we’ll grab the data in chunks.
import datetime
import json
from typing import Dict, List
import requests
def tprint(msg: str):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
print(f"[{timestamp}] {msg}")
def get_bnt_data(chunksize: int = 100000) -> List[Dict]:
url = "https://data.ny.gov/resource/qzve-kjga.json"
params = {"$limit": chunksize, "$offset": 0}
data: List[Dict] = []
while True:
tprint(f"Requesting chunk of {chunksize} with offset {params['$offset']}")
res = requests.get(url, params=params)
chunk = res.json()
tprint(f"Got chunk of size {len(chunk)}")
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize
tprint(f"Got {len(data)} records total")
return data
def write_local(data: List[Dict], fname: str = "bnt_traffic_hourly.json"):
tprint(f"Writing data to {fname}")
with open(fname, "w") as f:
json.dump(data, f)
tprint("Finished writing file")
def main():
data = get_bnt_data()
write_local(data)
if __name__ == "__main__":
main()
There are a number of things here I would avoid doing in production, including
hacking the print function to show timestamps rather than just using the
standard logging module. As we can see, nothing too fancy here, and this is
the solution I would use in a lot of my development.
The downside with this approach? The data is local, and therefore only available to your current machine (unless this is some NFS, but hey, I did say ‘local filesystem’). We’re now in a better position than relying on the public API, but if this data needs to be accessed from anywhere outside of our machine, we’re in a worse situation that just pulling the data from the API directly.
Storage Solution 2: JSON blob on Azure
If we’re happy enough with storing the data in the JSON format, but want to make sure we can grab this data from any of our processes possibly outside of our current machine, we can choose to store the data in some S3-like object store.
For no reason in particular, I’ll use Azure Blob store over AWS S3.
import datetime
import json
from argparse import ArgumentParser, Namespace
from typing import Dict, List
import requests
from azure.storage.blob import BlobClient
def tprint(msg: str):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
print(f"[{timestamp}] {msg}")
def get_bnt_data(chunksize: int = 100000) -> List[Dict]:
url = "https://data.ny.gov/resource/qzve-kjga.json"
params = {"$limit": chunksize, "$offset": 0}
data: List[Dict] = []
while True:
tprint(f"Requesting chunk of {chunksize} with offset {params['$offset']}")
res = requests.get(url, params=params)
chunk = res.json()
tprint(f"Got chunk of size {len(chunk)}")
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize
tprint(f"Got {len(data)} records total")
return data
def load_data_to_blob(
data: List[Dict],
account_url: str,
access_key: str,
container: str,
blob_name: str = "bnt_traffic_hourly.json",
):
blob = BlobClient(
account_url=account_url,
container_name=container,
blob_name=blob_name,
credential=access_key,
)
blob_data = json.dumps(data)
tprint(f"Writing data to {account_url}/{container}/{blob_name}")
blob.upload_blob(blob_data, overwrite=True)
tprint("Finished writing blob")
def main(args):
data = get_bnt_data()
load_data_to_blob(data, args.account_url, args.access_key, args.container)
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument("--account-url", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)
We can run this script, providing the proper credentials for your storage account and container, as such
$ python bridgeNtunnel_traffic/azure_json.py --account-url https://<your-storage-account>.blob.core.windows.net --container mta-demo --access-key <your-access-key>
After the API download logs, we’ll now see that our blob has been uploaded as expected.
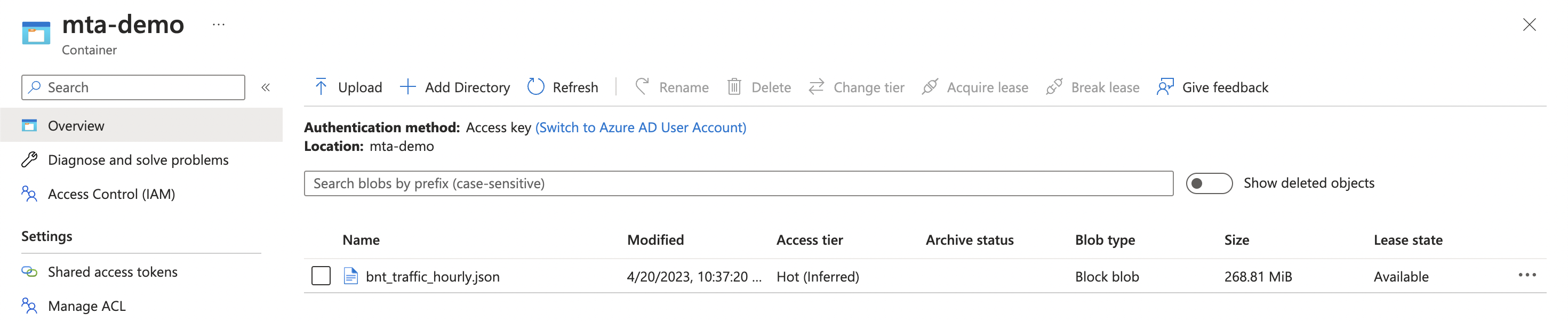
Storage Solution 3: Parquet on Azure
Now that our data is available on the cloud, the next step we may think about is the format of our data. One file format optimized storage and retrieval is parquet from Apache.
In order to take advantage of some of the efficiencies afforded to us by parquet, we’ll also make the jump from using python, to pyspark. Spark is my preferred analytics engine for large scale processing anyway, so this at least one step closer to how I would do things in production.
That said, in a production scenario, I would probably be combining Solution 2 with this solution, and moving the data first from the API to a json file, and then from json to parquet or some other format. My goal here is to keep these code blocks as copy-pasteable as possible for anyone who wants to play around with these solutions, so we’ll keep things self contained.
import datetime
from argparse import ArgumentParser, Namespace
from typing import Dict, List
import pyspark
import requests
from azure.storage.blob import BlobClient
from pyspark.sql import SparkSession
def tprint(msg: str):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
print(f"[{timestamp}] {msg}")
def get_bnt_data(chunksize: int = 100000) -> List[Dict]:
url = "https://data.ny.gov/resource/qzve-kjga.json"
url = "https://data.ny.gov/resource/vxuj-8kew.json"
params = {"$limit": chunksize, "$offset": 0}
data: List[Dict] = []
while True:
tprint(f"Requesting chunk of {chunksize} with offset {params['$offset']}")
res = requests.get(url, params=params)
chunk = res.json()
tprint(f"Got chunk of size {len(chunk)}")
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize
tprint(f"Got {len(data)} records total")
return data
def main(args):
data = get_bnt_data()
spark = SparkSession.builder.appName("mta-demo-azure-parquet").getOrCreate()
spark.conf.set(
f"fs.azure.account.key.{args.storage_account}.dfs.core.windows.net",
args.access_key,
)
df = spark.createDataFrame(data)
container_uri = (
f"abfss://{args.container}@{args.storage_account}.dfs.core.windows.net"
)
blob_name = "bnt_traffic_hourly.parquet"
df.write.save(f"{container_uri}/{blob_name}", format="parquet", mode="overwrite")
tprint(
f"Wrote data to https://{args.storage_account}.blob.core.windows.net/{args.container}/{blob_name}"
)
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)
One note, at the time of writing, python3.11 is out, however it seems pyspark 3.3.2(the version I’m using here) does not support python3.11 yet, and this can cause some issues. As a work around, you can use pyenv to grab an older version, say 3.10.4, and force pyspark to use that executable by setting
$ export PYSPARK_PYTHON=~/.pyenv/versions/3.10.4/bin/python
or wherever your pyenv root is.
To run this script, we’ll need to grab a few jars (again this isn’t how we would handle dependencies in a production environment)
$ wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure/3.3.2/hadoop-azure-3.3.2.jar
$ wget https://repo1.maven.org/maven2/com/azure/azure-storage-blob/12.22.0/azure-storage-blob-12.22.0.jar
And finally we can run submit this to our local spark instance
spark-submit --jars hadoop-azure-3.3.2.jar,azure-storage-blob-12.22.0.jar bridgeNtunnel_traffic/azure_parquet.py --storage-account <your-storage-account> --container mta-demo --access-key <your-access-key>
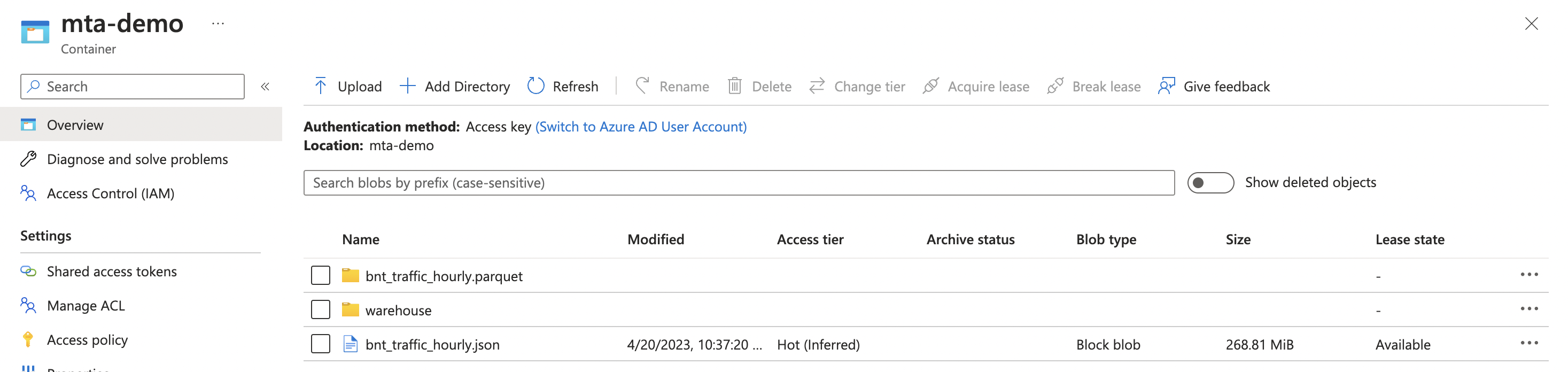
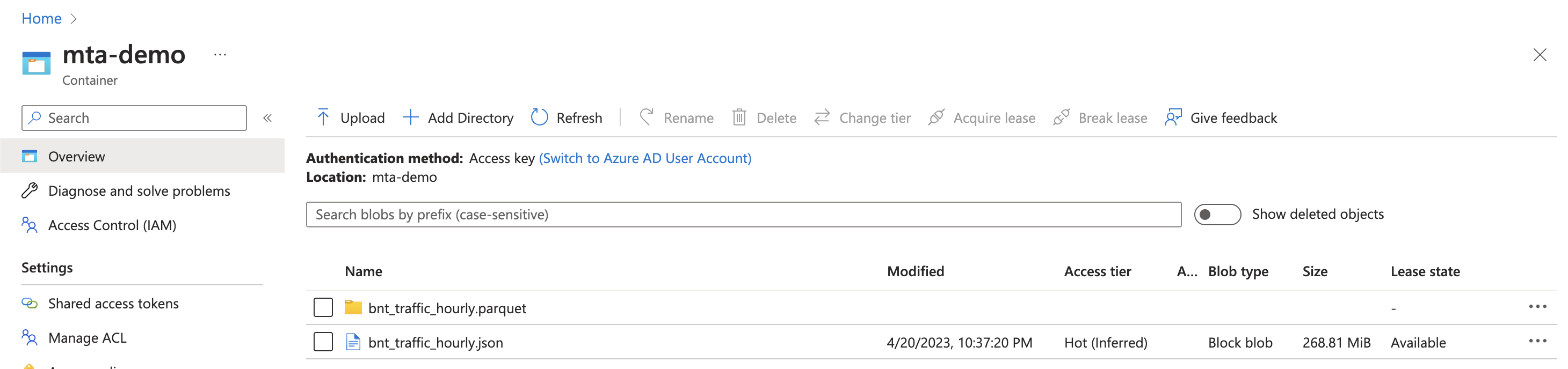
We can see significant improvements in write speed thanks to spark’s parallelization. Checking out our container, we notice a few things
-
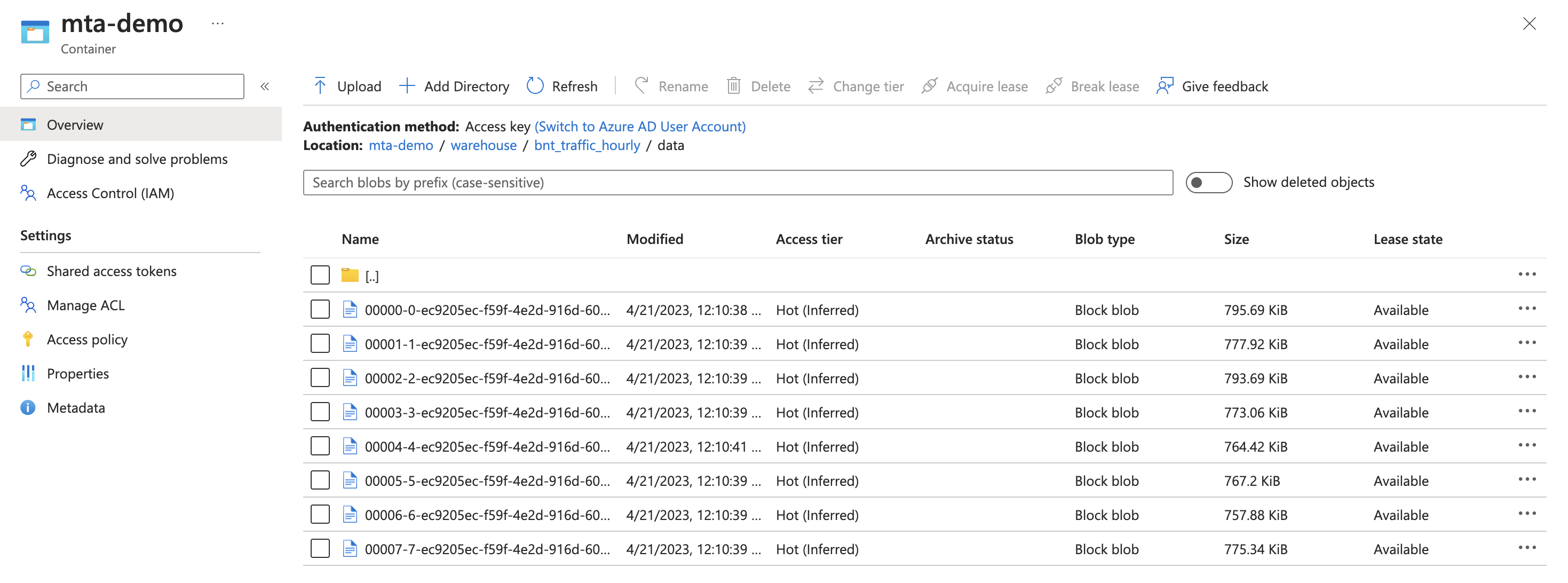
The most obvious, if you’re not familiar with spark, is that we didn’t write one file, but a directory(Technically, in blob storage this is just a prefix on every file name that looks like a directory). The reasons for this are outside the scope of this post, but this is normal and is due to spark’s parallel processing nature.
-
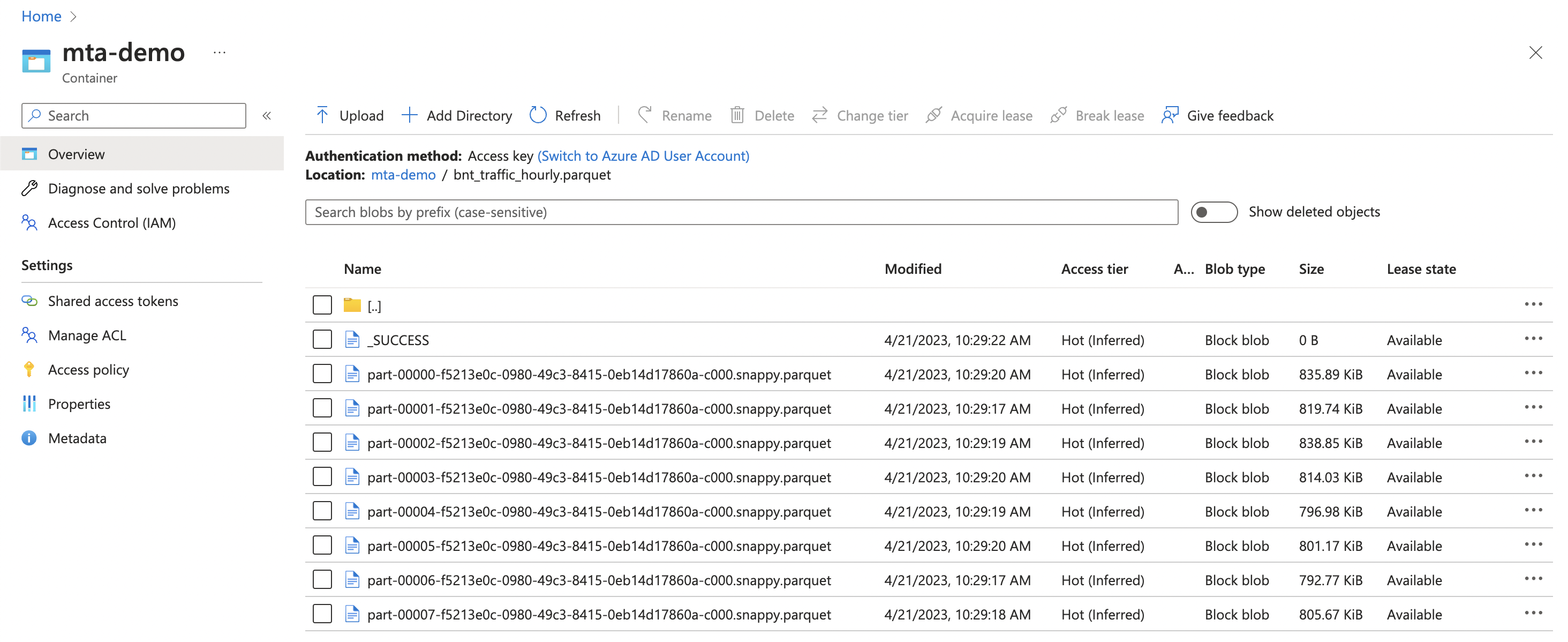
The total storage size is much less, ~6.4MiB vs the 269MiB JSON blob. The reason for this is that parquet itself is a binary format which is optimized for the compression being used here (snappy). So the parquet+snappy can result in extremely efficient compression.
Storage Solution 4: Iceberg on Azure
For our final solution, we’ll take a look at how we can create an Apache Iceberg table in Azure blob storage.
There are a lot of good articles out there on Iceberg and table formats in general, but the TLDR might be:
- Table formats give SQL-like semantics to files stored in a data lake
- Iceberg is an open table format, created to overcome the issues encountered when trying to use previous generation formats, i.e Hive, on the Cloud.
import datetime
from argparse import ArgumentParser, Namespace
from typing import Dict, List
import pyspark
import requests
from azure.storage.blob import BlobClient
from pyspark.sql import SparkSession
def tprint(msg: str):
timestamp = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S.%f")
print(f"[{timestamp}] {msg}")
def get_bnt_data(chunksize: int = 100000) -> List[Dict]:
url = "https://data.ny.gov/resource/qzve-kjga.json"
params = {"$limit": chunksize, "$offset": 0}
data: List[Dict] = []
while True:
tprint(f"Requesting chunk of {chunksize} with offset {params['$offset']}")
res = requests.get(url, params=params)
chunk = res.json()
tprint(f"Got chunk of size {len(chunk)}")
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize
tprint(f"Got {len(data)} records total")
return data
def main(args):
data = get_bnt_data()
spark = SparkSession.builder.appName("mta-demo-azure-iceberg").getOrCreate()
container_uri = (
f"abfss://{args.container}@{args.storage_account}.dfs.core.windows.net"
)
spark.conf.set(
f"fs.azure.account.key.{args.storage_account}.dfs.core.windows.net",
args.access_key,
)
spark.conf.set(
"spark.sql.catalog.mtademo", "org.apache.iceberg.spark.SparkCatalog"
)
spark.conf.set("spark.sql.catalog.mtademo.type", "hadoop")
spark.conf.set("spark.sql.catalog.mtademo.warehouse", f"{container_uri}/warehouse")
df = spark.createDataFrame(data)
df.writeTo("mtademo.bnt_traffic_hourly").create()
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)
We’ll need one more jar to run this script
$ wget https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.3_2.12/1.2.1/iceberg-spark-runtime-3.3_2.12-1.2.1.jar
And we can run this as before, including our new jar as well
spark-submit \
--jars hadoop-azure-3.3.2.jar,azure-storage-blob-12.22.0.jar,iceberg-spark-runtime-3.3_2.12-1.2.1.jar \
bridgeNtunnel_traffic/azure_iceberg.py --storage-account <your-storage-account> --container mta-demo --access-key <your-access-key>
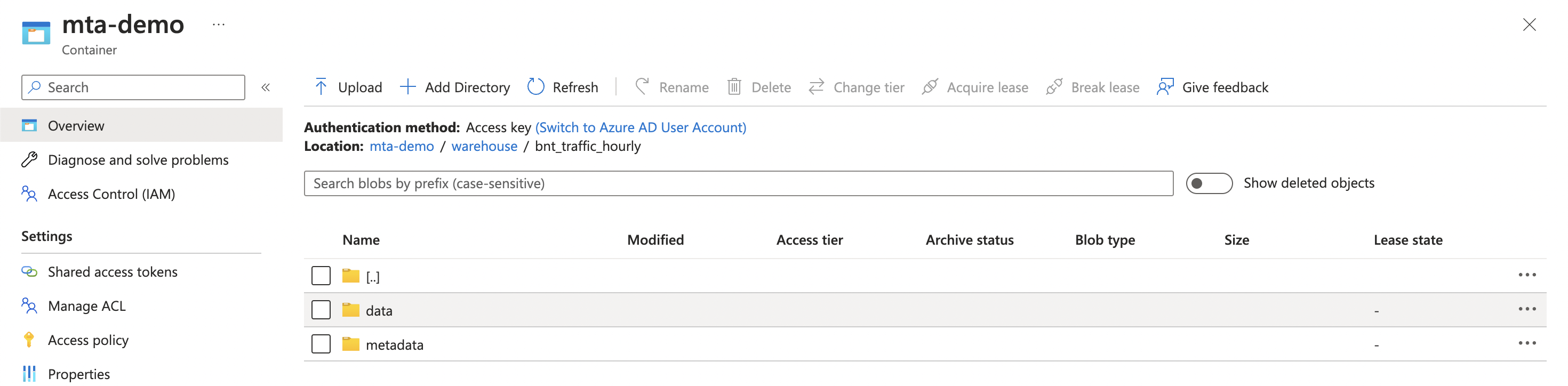
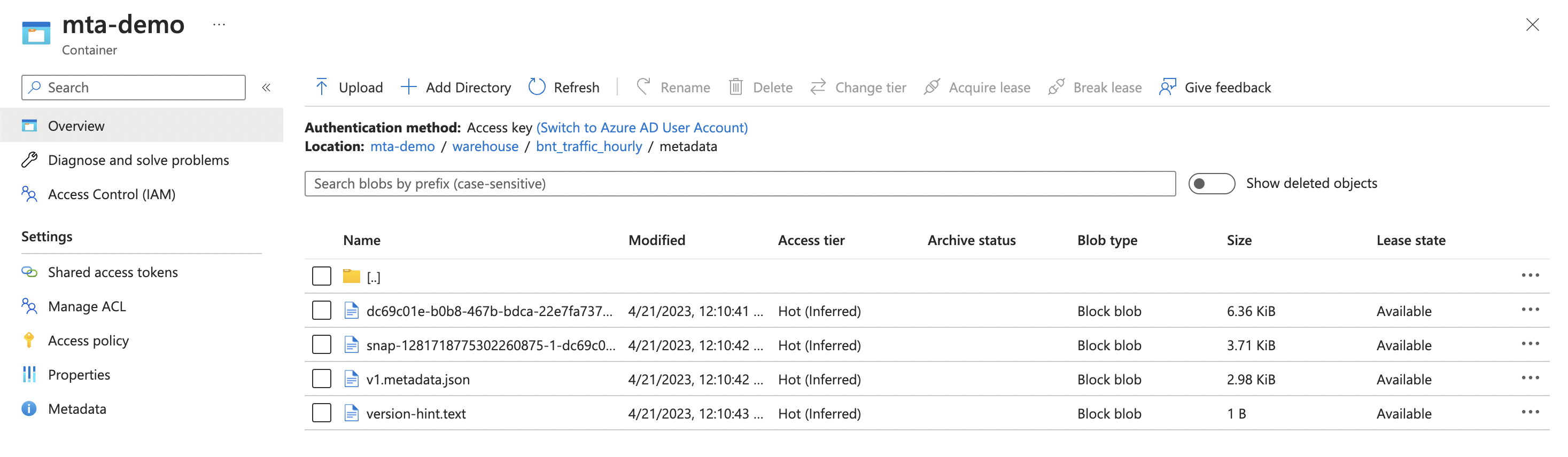
And with that, we can now see our data in the warehouse directory, along with
the metadata files that make up the catalog.