Remote Spark Execution Tasks in Prefect Flows using Databricks Connect
Continuing on our pipeline from Prefect Local Pipeline, one of the more stick pieces of our pipeline is the fact that we use
spark_submit on a local machine to execute our spark transformations. This is
at the very least annoying for a number of reasons:
- Getting a spark cluster running is enough of a pain locally, let alone doing so manually in a production environment.
- We need to make use of a subprocess to exeute the spark process, which forces us to communicate through stdin/stdout rather than using native python objects.
- Because we call this job from a subprocess, we need to separate our pipeline code from our ‘Spark Code’ which causes maintenance issues.
With all of this in mind, it is in fact very possible to run production
pipelines using this scheme (ask me how I know ![]() ). However, with the advent
of Databricks
Connect, and
more generally Spark Connect, we can simplify our
codebase and reduce the heavy lifting required to integrate Spark in our
pipelines.
). However, with the advent
of Databricks
Connect, and
more generally Spark Connect, we can simplify our
codebase and reduce the heavy lifting required to integrate Spark in our
pipelines.
Spinning up a Databricks Spark Cluster
In order to make use of a Databricks Spark cluster, we’ll need to create one. Once we create our cluster, we can terminate it so that it incurs no cost while we’re not using it. Conveniently, the Databricks Connect library will start up our cluster if it’s not running when we batch a job to it from our pipeline, so we don’t need to handle that explicitly in code.
In a production scenario, we would try to schedule most of our jobs utilizing the same cluster to run in the same time window and we configure the cluster to terminate automatically after some amount of idle time. Since having to restart the cluster for each run will increase time and cost, this setup can result in more streamlined pipelines for regularly scheduled runs.
For this demo, we can create a fairly slim single node cluster, since our pipeline code will be the same regardless of if we swap out a cluster with more resources (which is pretty awesome).
A few things we do want to make sure of when creating our cluster:
- Our Spark version should be 3.3.0, which at time of writing is the 11.3 LTS runtime. This is due to a compatibility with the Databricks Connect library, as well as iceberg, which at the time of writing does not yet support Spark 3.4.0
- We want to make sure to set the
Terminate Aftervalue to be something short, in our case 10 minutes, to ensure we aren’t incurring additional cost as the cluster sits idle. - Finally, we want to make sure that we set the following spark config
spark.databricks.service.server.enabled true. This is required for Databricks Connect to be enabled on the cluster for remote execution.
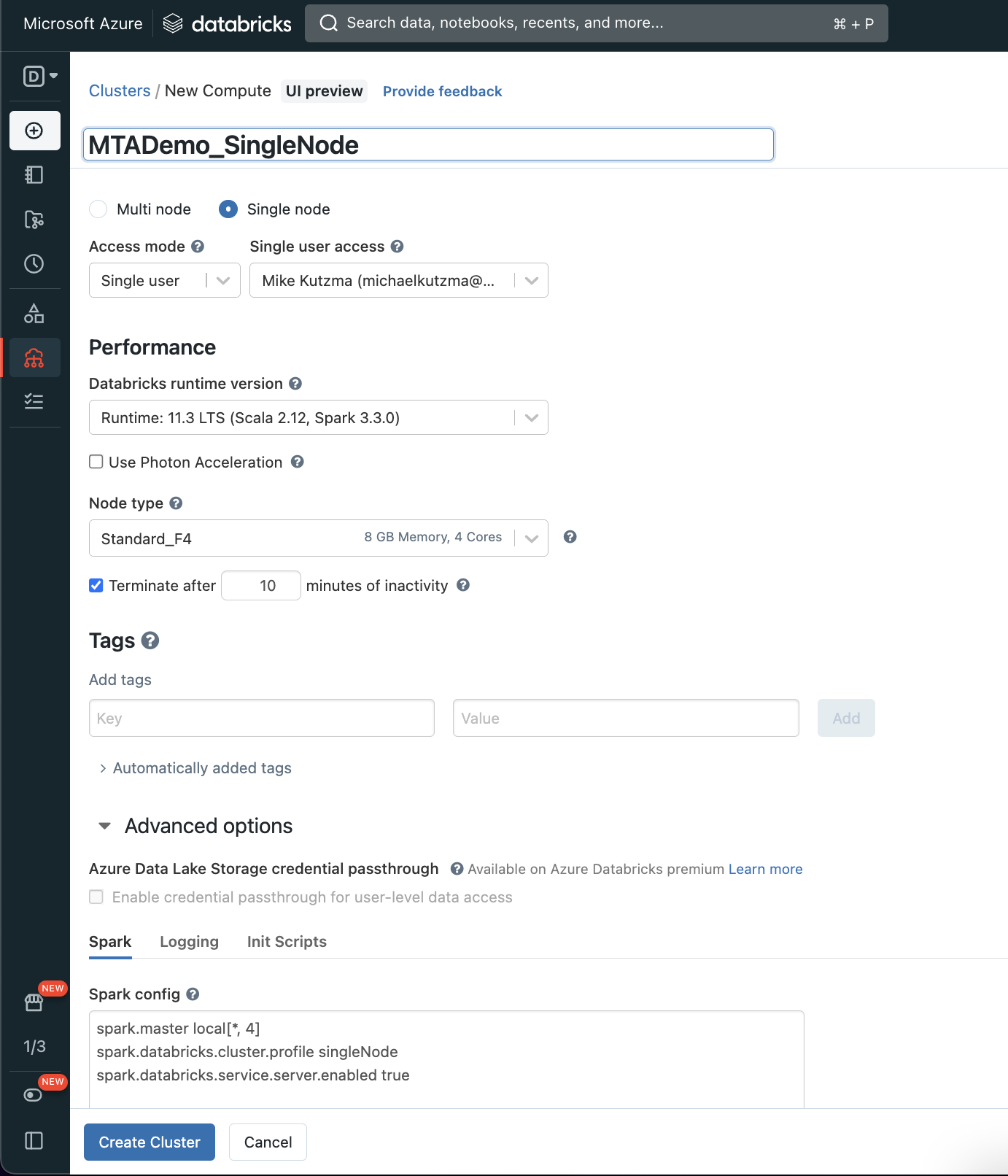
You can create the cluster either using the UI, or through the API (docs here). A sample payload for the API might look like
{
"num_workers": 0,
"cluster_name": "MTADemo_SingleNode",
"spark_version": "11.3.x-scala2.12",
"spark_conf": {
"spark.master": "local[*, 4]",
"spark.databricks.cluster.profile": "singleNode",
"spark.databricks.service.server.enabled": "true"
},
"azure_attributes": {
"first_on_demand": 1,
"availability": "ON_DEMAND_AZURE",
"spot_bid_max_price": -1
},
"node_type_id": "Standard_F4",
"driver_node_type_id": "Standard_F4",
"ssh_public_keys": [],
"custom_tags": {
"ResourceClass": "SingleNode"
},
"spark_env_vars": {},
"autotermination_minutes": 10,
"enable_elastic_disk": true,
"cluster_source": "UI",
"init_scripts": [],
"single_user_name": <your-databricks-username>,
"data_security_mode": "LEGACY_SINGLE_USER_STANDARD",
"runtime_engine": "STANDARD"
}
After creation, you’ll want to also add the following Maven libraries (which
can be done in the Libraries tab on the Cluster UI, or through the API (docs
here)
org.apache.hadoop:hadoop-azure:3.3.0org.apache.iceberg:iceberg-spark-runtime-3.3_2.12:1.2.1
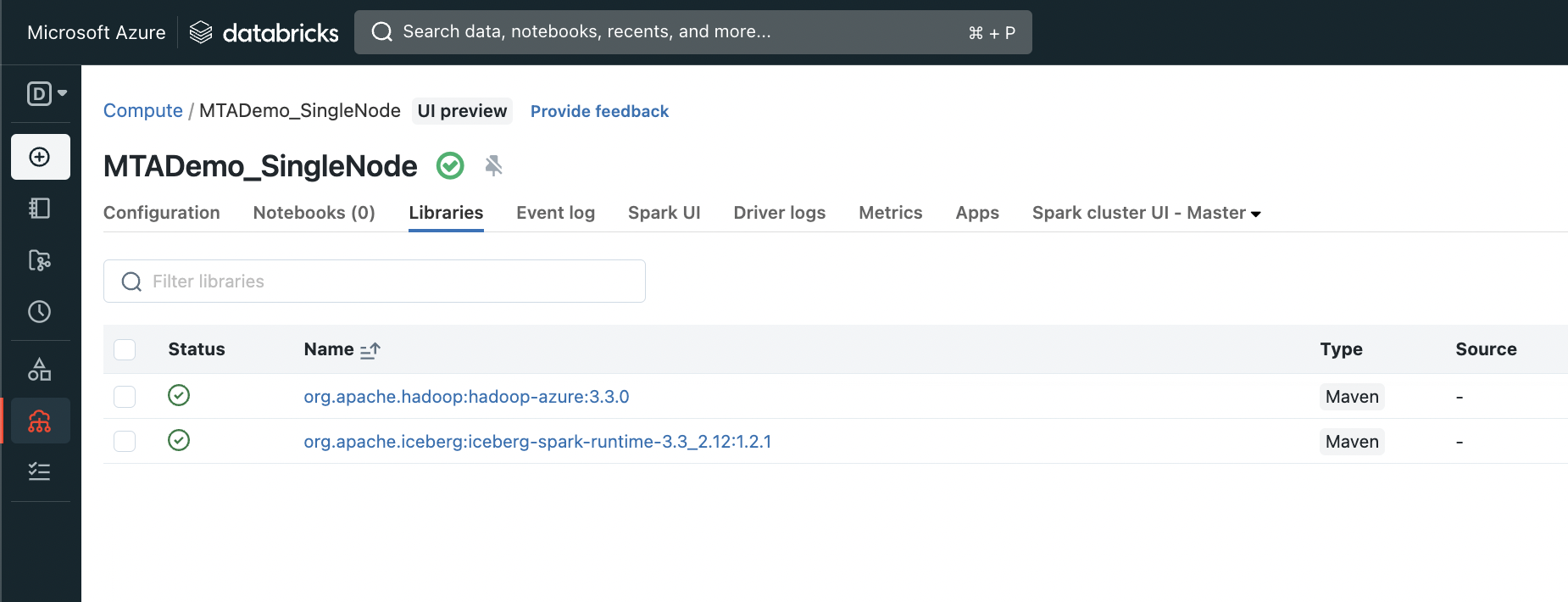
To be clear, a cluster only needs to be created once, whether through the API or through the UI, and can then be started/terminated/used as many times as needed.
Testing Our New Cluster
With our cluster created, let’s test that we can submit a job to it before
incorporating the transformation into the pipeline. We’ll assume that we have a
Bridge & Tunnel Traffic blob sitting in Azure to test with, as shown in Bridge
& Tunnel Data 4 Ways. As a starting point, we can
use our iceberg_loader.py script from Adding Spark Task.
Really the only thing we need to change code-wise is to add a few more spark configs, and add the new arguments to be passed. Our new test script should look like
import datetime
from argparse import ArgumentParser, Namespace
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
def main(args):
container_uri = (
f"abfss://{args.container}@{args.storage_account}.dfs.core.windows.net"
)
spark_configs = {
"spark.databricks.service.address": args.databricks_address,
"spark.databricks.service.token": args.databricks_token,
"spark.databricks.service.clusterId": args.databricks_cluster_id,
f"fs.azure.account.key.{args.storage_account}.dfs.core.windows.net": args.access_key,
"spark.sql.catalog.mtademo": "org.apache.iceberg.spark.SparkCatalog",
"spark.sql.catalog.mtademo.type": "hadoop",
"spark.sql.catalog.mtademo.warehouse": f"{container_uri}/warehouse",
}
builder = SparkSession.builder
for key, val in spark_configs.items():
builder = builder.config(key, val)
spark = builder.getOrCreate()
table_name = "mtademo.bronze.bnt_traffic_hourly"
create_query = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
plaza_id string,
date date,
hour string,
direction string,
vehicles_e_zpass int,
vehicles_vtoll int
)
USING iceberg
PARTITIONED BY (years(date))
"""
spark.sql(create_query).collect()
df = spark.read.json(f"{container_uri}/{args.blob_name}")
df = (
df.withColumn("date", F.to_date(df["date"]))
.withColumn("vehicles_e_zpass", df["vehicles_e_zpass"].cast("int"))
.withColumn("vehicles_vtoll", df["vehicles_vtoll"].cast("int"))
)
df.writeTo(table_name).append()
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
parser.add_argument("--blob-name", required=True)
parser.add_argument("--databricks-address", required=True)
parser.add_argument("--databricks-token", required=True)
parser.add_argument("--databricks-cluster-id", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)In order to run this, we’ll need to ensure the databricks connect library is
installed. The library version is strongly tied to the databricks runtime of
the cluster being used, so in this case we want version 11.3.*. On my machine
at least (a mac) I also need to drop an empty json object in the
~/.databricks-connect file, or else the code will prompt me to interactively
input some configs there, which we don’t want.
venv/bin/python -m pipe uninstall pyspark
venv/bin/python -m pip install "databricks-connect==11.3.*"
echo '{}' > ~/.databricks-connect
With our environment set up, we can now kick off our test script and confirm the connections between our local env, our databricks cluster, and our azure storage.
venv/bin/python iceberg_loader_databricks.py \
--storage-account <your-storage-account> \
--container mta-demo \
--access-key <your-access-key> \
--blob-name stage/bnt_traffic_hourly.json
--databricks-address <your-databricks-address> \
--databricks-token <your-databricks-token> \
--databricks-cluster-id <your-cluster-id>
One thing to notice is that we no longer need to run this script with
spark-submit, but rather can execute it natively from our python interpreter.
This will make things easier later when we want to embed this code in our
pipeline.
Integrating with Our Pipeline
With all the circuits checked, we can now update our pipeline tasks to use databricks connect rather than spark-submit subprocesses.
Essentially, the changes are just to replace our
load_azure_blob_to_iceberg_table task with two new spark-powered tasks,
create_bnt_iceberg_table and append_bnt_blob_to_iceberg.
def get_spark(configs: Dict[str, str]) -> SparkSession:
builder = SparkSession.builder
for key, val in configs.items():
builder = builder.config(key, val)
spark = builder.getOrCreate()
return spark
@task
def create_bnt_iceberg_table(
spark_configs: Dict[str, str],
table_name: str,
):
spark = get_spark(spark_configs)
create_query = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
plaza_id string,
date date,
hour string,
direction string,
vehicles_e_zpass int,
vehicles_vtoll int
)
USING iceberg
PARTITIONED BY (years(date))
"""
spark.sql(create_query).collect()
@task
def append_bnt_blob_to_iceberg(
spark_configs: Dict[str, str],
table_name: str,
blob_uri: str,
):
spark = get_spark(spark_configs)
df = spark.read.json(blob_uri)
df = (
df.withColumn("date", F.to_date(df["date"]))
.withColumn("vehicles_e_zpass", df["vehicles_e_zpass"].cast("int"))
.withColumn("vehicles_vtoll", df["vehicles_vtoll"].cast("int"))
)
df.writeTo(table_name).append()
By breaking these two processes up, we can schedule them more appropriately in our pipeline.
@flow
def pipeline(
start_date: datetime.date,
stop_date: datetime.date,
storage_account: str,
access_key: str,
container: str,
databricks_address: str,
databricks_token: str,
databricks_cluster_id: str,
):
container_uri = f"abfss://{container}@{storage_account}.dfs.core.windows.net"
blob_name = "stage/bnt_traffic_hourly.json"
catalog_name = "mtademo"
table_name = f"{catalog_name}.bronze.bnt_traffic_hourly"
spark_configs = {
"spark.databricks.service.address": databricks_address,
"spark.databricks.service.token": databricks_token,
"spark.databricks.service.clusterId": databricks_cluster_id,
f"fs.azure.account.key.{storage_account}.dfs.core.windows.net": access_key,
f"spark.sql.catalog.{catalog_name}": "org.apache.iceberg.spark.SparkCatalog",
f"spark.sql.catalog.{catalog_name}.type": "hadoop",
f"spark.sql.catalog.{catalog_name}.warehouse": f"{container_uri}/warehouse",
}
data = get_bnt_data.submit(
start_date,
stop_date,
)
table_created = create_bnt_iceberg_table.submit(
spark_configs,
table_name,
)
blob_loaded = load_to_azure_blob.submit(
data,
storage_account,
access_key,
container,
blob_name,
wait_for=[data],
)
append_bnt_blob_to_iceberg.submit(
spark_configs,
table_name,
f"{container_uri}/{blob_name}",
wait_for=[table_created, blob_loaded],
)
By making use of .submit to execute our tasks, Prefect will make use of the
ConcurrentTaskRunner, and execute our various tasks concurrently. However, we
do have dependencies between our tasks, for example, we can’t append our blob
to our iceberg table until we’ve madde sure that our table has been created. To
handle dependencies, we pass the wait_for argument in our submit call, where
the argument should be the list of task futures (basically the object
returned by calling .submit on a task) that this task is dependent on.
The above pipeline gives us a dependency graph that looks like
Finally, we can execute our pipeline and confirm it runs successfully.
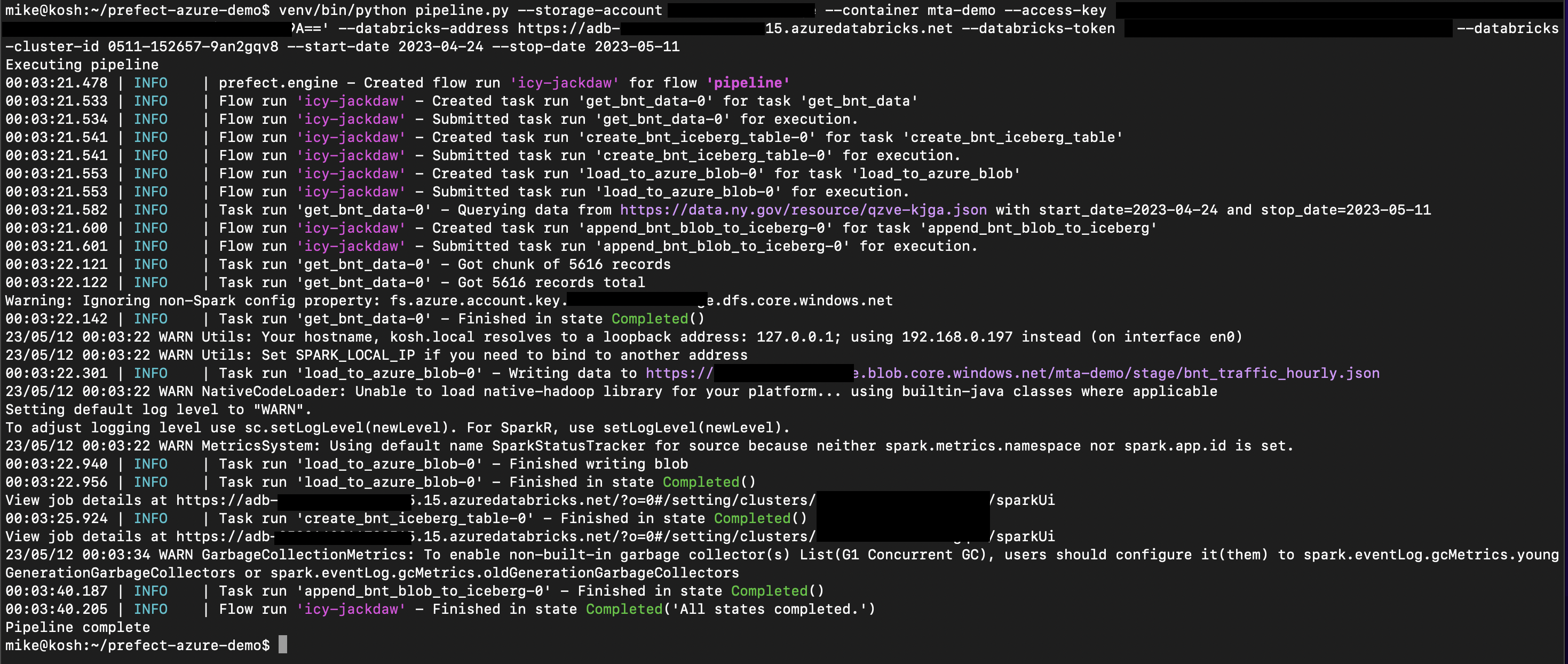
In the next post, we’ll improve our pipeline orchestration by making use of the Prefect Server, Blocks, and Deployments.
Final pipeline
import datetime
import json
from argparse import ArgumentParser, Namespace
from typing import Dict, List, Optional
import pyspark.sql.functions as F
import requests
from azure.storage.blob import BlobClient
from prefect import flow, get_run_logger, task
from pyspark.sql import SparkSession
def get_spark(configs: Dict[str, str]) -> SparkSession:
builder = SparkSession.builder
for key, val in configs.items():
builder = builder.config(key, val)
spark = builder.getOrCreate()
return spark
@task
def get_bnt_data(
start_date: datetime.date,
stop_date: Optional[datetime.date] = None,
chunksize: int = 100000,
) -> List[Dict]:
_logger = get_run_logger()
url = "https://data.ny.gov/resource/qzve-kjga.json"
start_date_str = start_date.strftime("%Y-%m-%dT00:00:00.00")
where_clause = f'date>="{start_date_str}"'
if stop_date:
stop_date_str = stop_date.strftime("%Y-%m-%dT00:00:00.00")
where_clause = f'{where_clause} and date<"{stop_date_str}"'
params = {"$limit": chunksize, "$offset": 0, "$where": where_clause}
data: List[Dict] = []
_logger.info(
"Querying data from %s with start_date=%s and stop_date=%s",
url,
start_date,
stop_date,
)
while True:
res = requests.get(url, params=params)
res.raise_for_status()
chunk = res.json()
_logger.info("Got chunk of %d records", len(chunk))
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize # type: ignore
_logger.info("Got %d records total", len(data))
return data
@task
def load_to_azure_blob(
data: List[Dict],
storage_account: str,
access_key: str,
container: str,
blob_name: str,
):
_logger = get_run_logger()
account_url = f"https://{storage_account}.blob.core.windows.net"
blob = BlobClient(
account_url=account_url,
container_name=container,
blob_name=blob_name,
credential=access_key,
)
blob_data = json.dumps(data)
_logger.info("Writing data to %s", f"{account_url}/{container}/{blob_name}")
blob.upload_blob(blob_data, overwrite=True)
_logger.info("Finished writing blob")
@task
def create_bnt_iceberg_table(
spark_configs: Dict[str, str],
table_name: str,
):
spark = get_spark(spark_configs)
create_query = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
plaza_id string,
date date,
hour string,
direction string,
vehicles_e_zpass int,
vehicles_vtoll int
)
USING iceberg
PARTITIONED BY (years(date))
"""
spark.sql(create_query).collect()
@task
def append_bnt_blob_to_iceberg(
spark_configs: Dict[str, str],
table_name: str,
blob_uri: str,
):
spark = get_spark(spark_configs)
df = spark.read.json(blob_uri)
df = (
df.withColumn("date", F.to_date(df["date"]))
.withColumn("vehicles_e_zpass", df["vehicles_e_zpass"].cast("int"))
.withColumn("vehicles_vtoll", df["vehicles_vtoll"].cast("int"))
)
df.writeTo(table_name).append()
@flow
def pipeline(
start_date: datetime.date,
stop_date: datetime.date,
storage_account: str,
access_key: str,
container: str,
databricks_address: str,
databricks_token: str,
databricks_cluster_id: str,
):
container_uri = f"abfss://{container}@{storage_account}.dfs.core.windows.net"
blob_name = "stage/bnt_traffic_hourly.json"
catalog_name = "mtademo"
table_name = f"{catalog_name}.bronze.bnt_traffic_hourly"
spark_configs = {
"spark.databricks.service.address": databricks_address,
"spark.databricks.service.token": databricks_token,
"spark.databricks.service.clusterId": databricks_cluster_id,
f"fs.azure.account.key.{storage_account}.dfs.core.windows.net": access_key,
f"spark.sql.catalog.{catalog_name}": "org.apache.iceberg.spark.SparkCatalog",
f"spark.sql.catalog.{catalog_name}.type": "hadoop",
f"spark.sql.catalog.{catalog_name}.warehouse": f"{container_uri}/warehouse",
}
data = get_bnt_data.submit(
start_date,
stop_date,
)
table_created = create_bnt_iceberg_table.submit(
spark_configs,
table_name,
)
blob_loaded = load_to_azure_blob.submit(
data,
storage_account,
access_key,
container,
blob_name,
wait_for=[data],
)
append_bnt_blob_to_iceberg.submit(
spark_configs,
table_name,
f"{container_uri}/{blob_name}",
wait_for=[table_created, blob_loaded],
)
def main(args: Namespace):
print("Executing pipeline")
pipeline(
start_date=args.start_date,
stop_date=args.stop_date,
storage_account=args.storage_account,
access_key=args.access_key,
container=args.container,
databricks_address=args.databricks_address,
databricks_token=args.databricks_token,
databricks_cluster_id=args.databricks_cluster_id,
)
print("Pipeline complete")
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument(
"--start-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Starting date to pull data for",
required=True,
)
parser.add_argument(
"--stop-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Stop date to pull data for",
required=False,
)
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
parser.add_argument("--databricks-address", required=True)
parser.add_argument("--databricks-token", required=True)
parser.add_argument("--databricks-cluster-id", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)