Prefect Local Pipeline
- Orchestration: Local
- Compute: Local
- Storage: Cloud
In this demo, we’ll build a pipeline using Prefect that will extract and
process data from the MTA Bridge and Tunnel Hourly Traffic
Dataset,
and do some downstream analysis.
Our pipeline will have the following steps:
- Pull new data from the Bridge and Tunnel API
- Ingest into Iceberg table
Prerequisites
I won’t spend too much time on the how around installing these (there are better tutorials floating around), but more on what exactly the prerequisites I’ll assume are.
Prefect
Prefect is the main tool we’ll be using to orchestrate our pipelines. In this post, we’ll use prefect locally, without even running the prefect server, so the install is pretty basic. We’ll also install some other dependencies we’ll use later in our virtualenv.
mkdir prefect-azure-demo && cd prefect-azure-demo
python -m venv venv
venv/bin/python -m pip install prefect azure-storage-blob
venv/bin/pip freeze > requirements.txt
Spark
We’ll make use of Spark for some of our transformation tasks, so we’ll want Spark running locally as well. Installing a local spark cluster is outside of the scope of this post, we’ll assume Spark3.3.2. Some resources:
We’ll also need a few jars that will allow us to load data into Azure and on Azure, into Iceberg tables. For now, we’ll just grab them locally
wget https://repo1.maven.org/maven2/org/apache/hadoop/hadoop-azure/3.3.2/hadoop-azure-3.3.2.jar
wget https://repo1.maven.org/maven2/com/azure/azure-storage-blob/12.22.0/azure-storage-blob-12.22.0.jar
wget https://repo1.maven.org/maven2/org/apache/iceberg/iceberg-spark-runtime-3.3_2.12/1.2.1/iceberg-spark-runtime-3.3_2.12-1.2.1.jar
Azure Storage
For setting up the storage accout, the Azure Docs do a better job than I would, probably just follow those.
Once you storage account if set up, create a new container to dump the data,
we’ll call it mta-demo.
Pipeline Construction
First, we’ll set up a basic pipeline consisting of a single flow, and two tasks:
- Pull data from API
- Load data to local json
This will allow us to check the initial circuits, and understand what it looks like to run prefect locally.
import datetime
import json
from argparse import ArgumentParser, Namespace
from typing import Dict, List, Optional
import requests
from azure.storage.blob import BlobClient
from prefect import flow, get_run_logger, task
@task
def get_bnt_data(
start_date: datetime.date,
stop_date: Optional[datetime.date] = None,
chunksize: int = 10000,
) -> List[Dict]:
_logger = get_run_logger()
url = "https://data.ny.gov/resource/qzve-kjga.json"
start_date_str = start_date.strftime("%Y-%m-%dT00:00:00.00")
where_clause = f'date>="{start_date_str}"'
if stop_date:
stop_date_str = stop_date.strftime("%Y-%m-%dT00:00:00.00")
where_clause = f'{where_clause} and date<"{stop_date_str}"'
params = {"$limit": chunksize, "$offset": 0, "$where": where_clause}
data: List[Dict] = []
_logger.info(
"Querying data from %s with start_date=%s and stop_date=%s",
url,
start_date,
stop_date,
)
while True:
res = requests.get(url, params=params)
res.raise_for_status()
chunk = res.json()
_logger.info("Got chunk of %d records", len(chunk))
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize # type: ignore
_logger.info("Got %d records total", len(data))
return data
@task
def write_locally(data: List[Dict]):
_logger = get_run_logger()
outfile = "chunk.json"
_logger.info("Writing file to %s", outfile)
with open(outfile, "w") as f:
json.dump(data, f)
@flow
def pipeline(start_date: datetime.date):
data = get_bnt_data(args.start_date, args.stop_date)
write_locally(data)
def main(args: Namespace):
print("Executing pipeline")
pipeline(start_date=args.start_date)
print("Pipeline complete")
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument(
"--start-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Starting date to pull data for",
required=True,
)
parser.add_argument(
"--stop-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Stop date to pull data for",
required=False,
)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
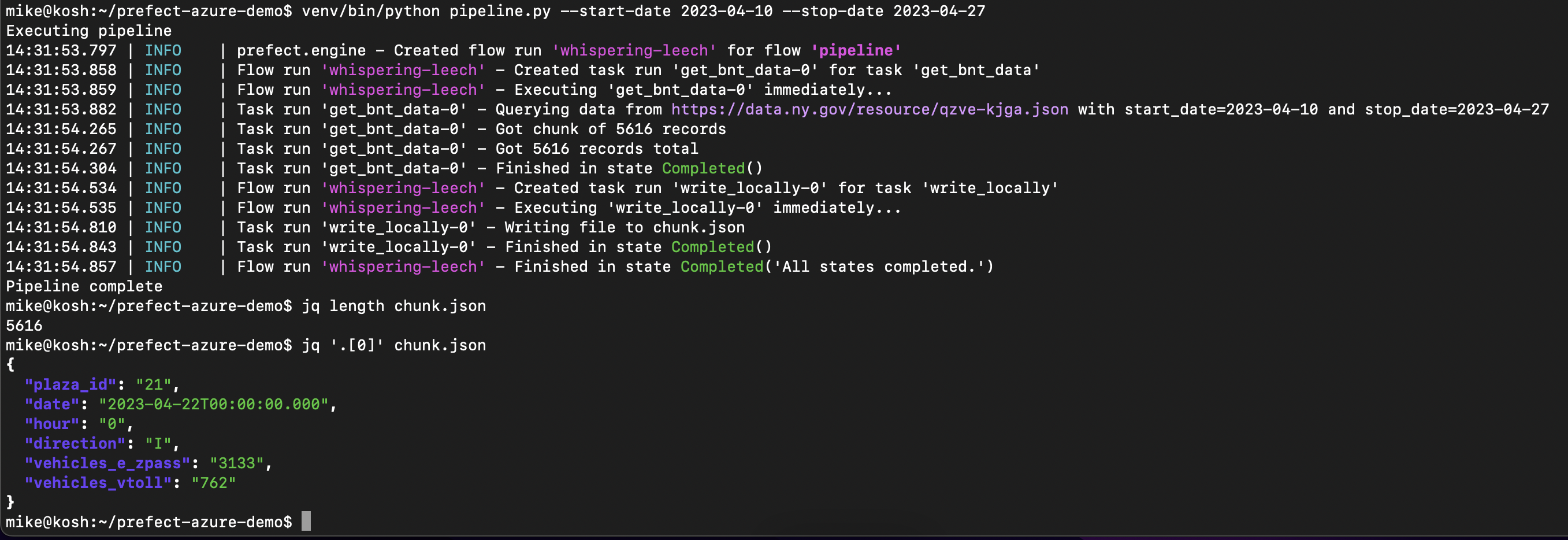
main(args)Running this pipeline, we can see data being successfully extracted and loaded
into a local json file.
 With this working, we can swap out our local storage with our azure storage.
With this working, we can swap out our local storage with our azure storage.
To do this, we’ll replace our write_locally task with a new
write_to_azure_blob task
@task
def load_to_azure_blob(
data: List[Dict],
storage_account: str,
access_key: str,
container: str,
blob_name: str,
):
_logger = get_run_logger()
account_url = f"https://{storage_account}.blob.core.windows.net"
blob = BlobClient(
account_url=account_url,
container_name=container,
blob_name=blob_name,
credential=access_key,
)
blob_data = json.dumps(data)
_logger.info("Writing data to %s", f"{account_url}/{container}/{blob_name}")
blob.upload_blob(blob_data, overwrite=True)
_logger.info("Finished writing blob")
Next we’ll update our flow to call this new task in place of our old one
@flow
def pipeline(
start_date: datetime.date,
stop_date: datetime.date,
storage_account: str,
access_key: str,
container: str,
):
data = get_bnt_data(args.start_date, args.stop_date)
blob_name = "stage/bnt_traffic_hourly.json"
load_to_azure_blob(data, storage_account, access_key, container, blob_name)
And finally we just need to update our get_args and main methods to allow
for passing these new azure arguments
def main(args: Namespace):
print("Executing pipeline")
pipeline(
start_date=args.start_date,
stop_date=args.stop_date,
storage_account=args.storage_account,
access_key=args.access_key,
container=args.container,
)
print("Pipeline complete")
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument(
"--start-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Starting date to pull data for",
required=True,
)
parser.add_argument(
"--stop-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Stop date to pull data for",
required=False,
)
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
args = parser.parse_args()
return args
We can then run this with
venv/bin/python pipeline.py \
--start-date 2023-04-10 \
--stop-date 2023-04-27 \
--storage-account <your-storage-account> \
--container mta-demo \
--access-key '<your-access-key>'
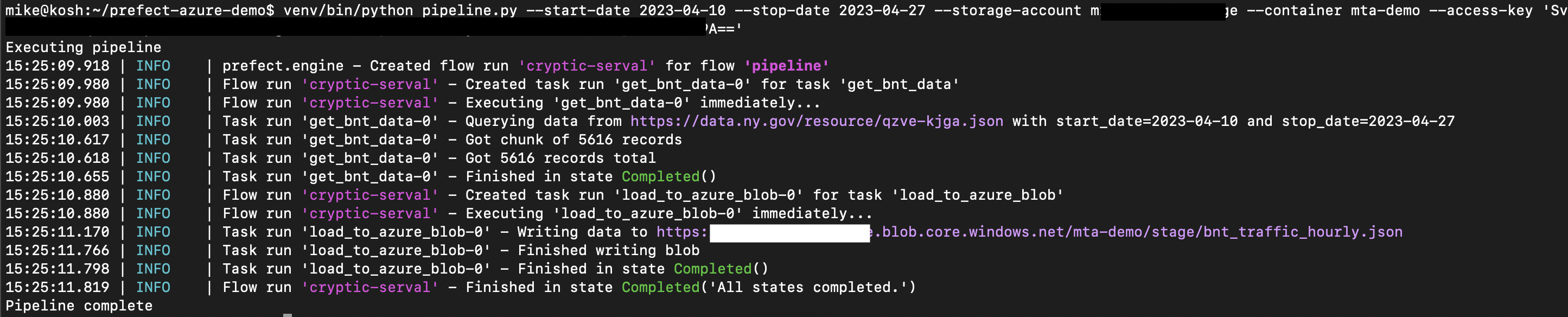
After which we should see successful logs
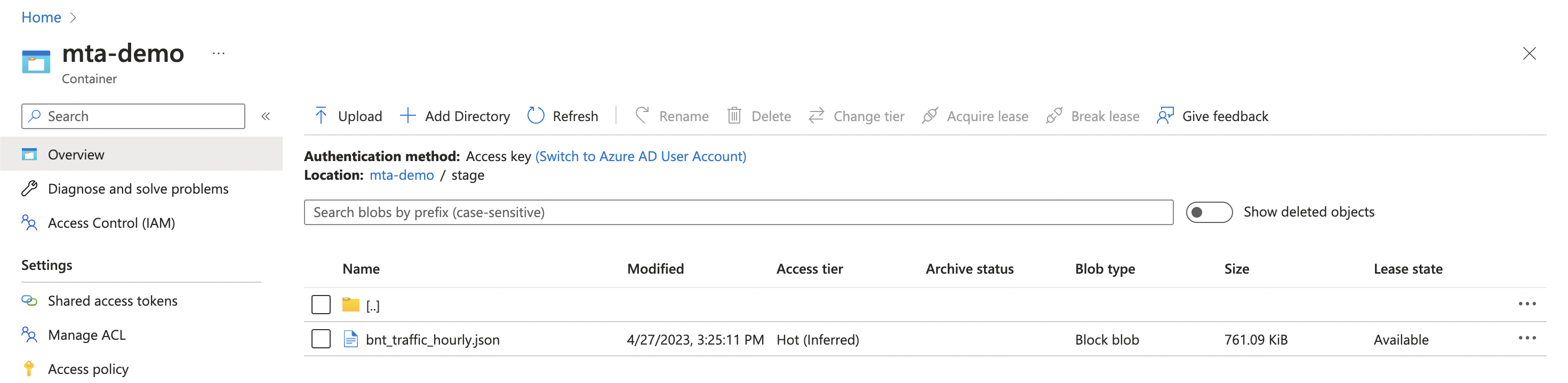
 And upon checking our container, we can now see the blob in our new staging zone
And upon checking our container, we can now see the blob in our new staging zone
Adding Spark Task
We’re ready to now add a second step in our pipeline, namely ingesting our staged blob into an Iceberg table.
To do so, we’ll write a pyspark script to read the blob, perform some transformations, and append to the table.
Our script looks like this
import datetime
from argparse import ArgumentParser, Namespace
import pyspark.sql.functions as F
from pyspark.sql import SparkSession
def main(args):
spark = SparkSession.builder.appName("mta-demo").getOrCreate()
container_uri = (
f"abfss://{args.container}@{args.storage_account}.dfs.core.windows.net"
)
spark.conf.set(
f"fs.azure.account.key.{args.storage_account}.dfs.core.windows.net",
args.access_key,
)
spark.conf.set("spark.sql.catalog.mtademo", "org.apache.iceberg.spark.SparkCatalog")
spark.conf.set("spark.sql.catalog.mtademo.type", "hadoop")
spark.conf.set("spark.sql.catalog.mtademo.warehouse", f"{container_uri}/warehouse")
table_name = "mtademo.bronze.bnt_traffic_hourly"
create_query = f"""
CREATE TABLE IF NOT EXISTS {table_name} (
plaza_id string,
date date,
hour string,
direction string,
vehicles_e_zpass int,
vehicles_vtoll int
)
USING iceberg
PARTITIONED BY (date)
"""
spark.sql(create_query).show()
df = spark.read.json(f"{container_uri}/{args.blob_name}")
df = (
df.withColumn("date", F.to_date(df["date"]))
.withColumn("vehicles_e_zpass", df["vehicles_e_zpass"].cast("int"))
.withColumn("vehicles_vtoll", df["vehicles_vtoll"].cast("int"))
)
df.writeTo(table_name).append()
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
parser.add_argument("--blob-name", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)To test, we can even spark-submit our script directly from outside of the pipeline with
spark-submit \
--jars hadoop-azure-3.3.2.jar,azure-storage-blob-12.22.0.jar,iceberg-spark-runtime-3.3_2.12-1.2.1.jar \
bridgeNtunnel_traffic/azure_iceberg.py \
--storage-account <your-storage-account> \
--container mta-demo \
--access-key <your-access-key> \
--blob-name stage/bnt_traffic_hourly.json
In order to incorporate this into our pipeline, since we are just calling spark locally, we can use a subprocess call. Our new task (and help function) will look like
@task
def load_azure_blob_to_iceberg_table(
storage_account: str,
access_key: str,
container: str,
blob_name: str,
spark_submit_executable: str,
):
_logger = get_run_logger()
jars = [
"hadoop-azure-3.3.2.jar",
"azure-storage-blob-12.22.0.jar",
"iceberg-spark-runtime-3.3_2.12-1.2.1.jar",
]
_logger.info(
"Executing %s with spark_submit at %s",
iceberg_loader.__file__,
spark_submit_executable,
)
spark_submit(
iceberg_loader,
spark_submit_executable,
jars,
storage_account=storage_account,
access_key=access_key,
container=container,
blob_name=blob_name,
)
def spark_submit(
spark_module, spark_submit_executable: str, jars: List[str] = [], **kwargs
):
command = [spark_submit_executable]
if jars:
command.extend(["--jars", ",".join(jars)])
command.extend([spark_module.__file__])
if kwargs:
args = [(f"--{key.replace('_', '-')}", value) for key, value in kwargs.items()]
command.extend([x for pair in args for x in pair])
out = subprocess.run(command, capture_output=True)
return out
And our updated pipeline will look like
@flow
def pipeline(
start_date: datetime.date,
stop_date: datetime.date,
storage_account: str,
access_key: str,
container: str,
spark_submit_executable: str,
):
data = get_bnt_data(args.start_date, args.stop_date)
blob_name = "stage/bnt_traffic_hourly.json"
load_to_azure_blob(data, storage_account, access_key, container, blob_name)
load_azure_blob_to_iceberg_table(
storage_account, access_key, container, blob_name, args.spark_submit_executable
)
where spark_submit_executable is the path to our local spark-submit command.
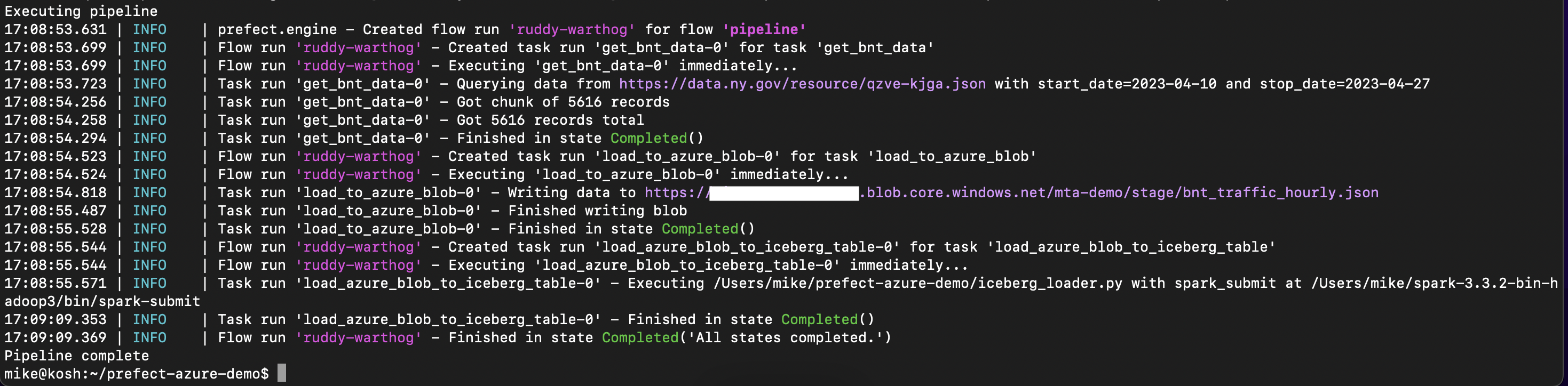
Upon running our new pipeline, we’ll now see our spark job being submitted after the api task
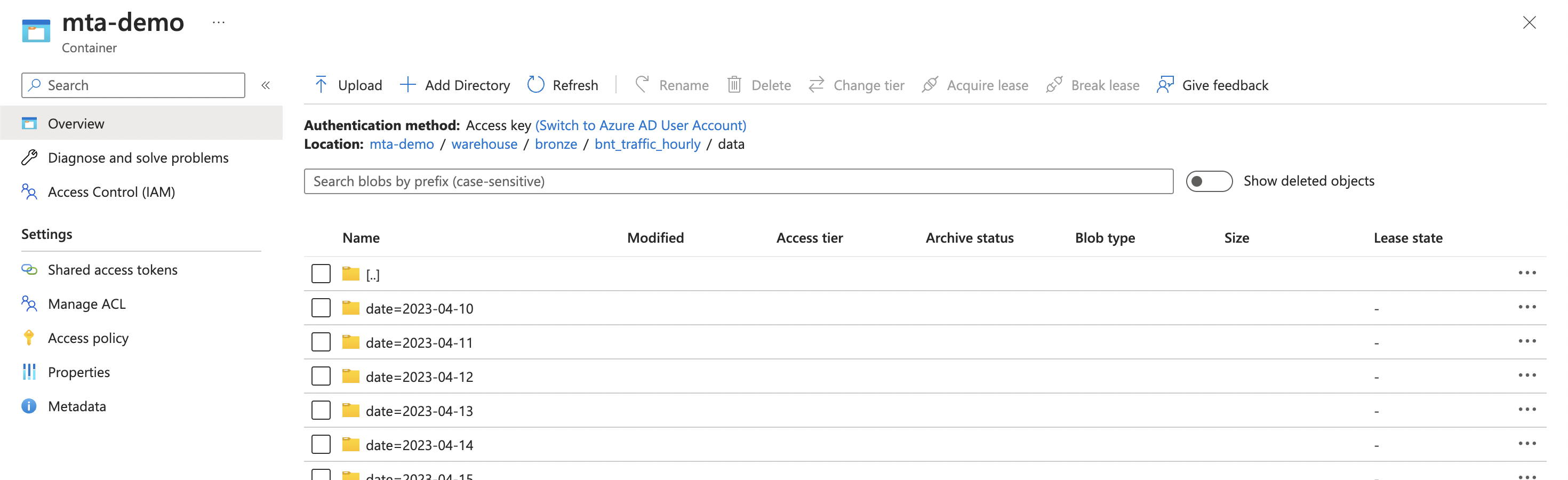
 And checking out our iceberg table, we can follow the directories to the data
directory and see our paritioned data
And checking out our iceberg table, we can follow the directories to the data
directory and see our paritioned data
 Opening up a pyspark repl and initializing our connection parameters as in the
Opening up a pyspark repl and initializing our connection parameters as in the
iceberg_loader.py script, we can now query our table using sql syntax
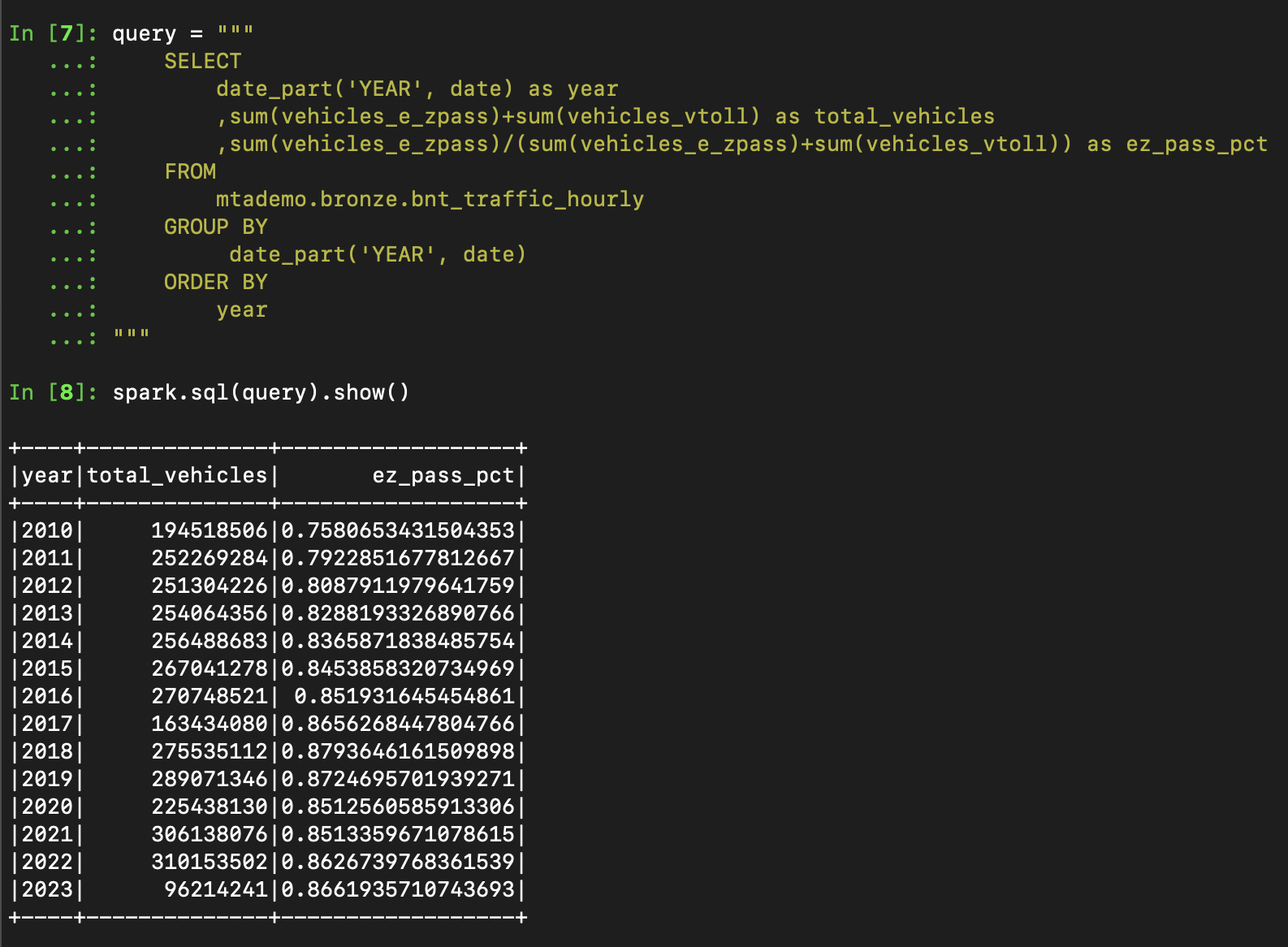
This completes our demo, with our final pipeline script in full looking like
import datetime
import json
import subprocess
from argparse import ArgumentParser, Namespace
from typing import Dict, List, Optional
import requests
from azure.storage.blob import BlobClient
from prefect import flow, get_run_logger, task
import iceberg_loader
@task
def get_bnt_data(
start_date: datetime.date,
stop_date: Optional[datetime.date] = None,
chunksize: int = 100000,
) -> List[Dict]:
_logger = get_run_logger()
url = "https://data.ny.gov/resource/qzve-kjga.json"
start_date_str = start_date.strftime("%Y-%m-%dT00:00:00.00")
where_clause = f'date>="{start_date_str}"'
if stop_date:
stop_date_str = stop_date.strftime("%Y-%m-%dT00:00:00.00")
where_clause = f'{where_clause} and date<"{stop_date_str}"'
params = {"$limit": chunksize, "$offset": 0, "$where": where_clause}
data: List[Dict] = []
_logger.info(
"Querying data from %s with start_date=%s and stop_date=%s",
url,
start_date,
stop_date,
)
while True:
res = requests.get(url, params=params)
res.raise_for_status()
chunk = res.json()
_logger.info("Got chunk of %d records", len(chunk))
data.extend(chunk)
if len(chunk) < chunksize:
break
else:
params["$offset"] = params["$offset"] + chunksize # type: ignore
_logger.info("Got %d records total", len(data))
return data
@task
def load_to_azure_blob(
data: List[Dict],
storage_account: str,
access_key: str,
container: str,
blob_name: str,
):
_logger = get_run_logger()
account_url = f"https://{storage_account}.blob.core.windows.net"
blob = BlobClient(
account_url=account_url,
container_name=container,
blob_name=blob_name,
credential=access_key,
)
blob_data = json.dumps(data)
_logger.info("Writing data to %s", f"{account_url}/{container}/{blob_name}")
blob.upload_blob(blob_data, overwrite=True)
_logger.info("Finished writing blob")
@task
def load_azure_blob_to_iceberg_table(
storage_account: str,
access_key: str,
container: str,
blob_name: str,
spark_submit_executable: str,
):
_logger = get_run_logger()
jars = [
"hadoop-azure-3.3.2.jar",
"azure-storage-blob-12.22.0.jar",
"iceberg-spark-runtime-3.3_2.12-1.2.1.jar",
]
_logger.info(
"Executing %s with spark_submit at %s",
iceberg_loader.__file__,
spark_submit_executable,
)
spark_submit(
iceberg_loader,
spark_submit_executable,
jars,
storage_account=storage_account,
access_key=access_key,
container=container,
blob_name=blob_name,
)
def spark_submit(
spark_module, spark_submit_executable: str, jars: List[str] = [], **kwargs
):
command = [spark_submit_executable]
if jars:
command.extend(["--jars", ",".join(jars)])
# Uncomment for large local backfill runs
# command.extend(["--driver-memory", "8g", "--master", "local[*]"])
command.extend([spark_module.__file__])
if kwargs:
args = [(f"--{key.replace('_', '-')}", value) for key, value in kwargs.items()]
command.extend([x for pair in args for x in pair])
out = subprocess.run(command, capture_output=True, check=True)
return out
@flow
def pipeline(
start_date: datetime.date,
stop_date: datetime.date,
storage_account: str,
access_key: str,
container: str,
spark_submit_executable: str,
):
data = get_bnt_data(args.start_date, args.stop_date)
blob_name = "stage/bnt_traffic_hourly.json"
load_to_azure_blob(data, storage_account, access_key, container, blob_name)
load_azure_blob_to_iceberg_table(
storage_account, access_key, container, blob_name, args.spark_submit_executable
)
def main(args: Namespace):
print("Executing pipeline")
pipeline(
start_date=args.start_date,
stop_date=args.stop_date,
storage_account=args.storage_account,
access_key=args.access_key,
container=args.container,
spark_submit_executable=args.spark_submit_executable,
)
print("Pipeline complete")
def get_args() -> Namespace:
parser = ArgumentParser()
parser.add_argument(
"--start-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Starting date to pull data for",
required=True,
)
parser.add_argument(
"--stop-date",
type=lambda d: datetime.datetime.strptime(d, "%Y-%m-%d").date(),
help="Stop date to pull data for",
required=False,
)
parser.add_argument("--storage-account", required=True)
parser.add_argument("--access-key", required=True)
parser.add_argument("--container", required=True)
parser.add_argument("--spark-submit-executable", required=True)
args = parser.parse_args()
return args
if __name__ == "__main__":
args = get_args()
main(args)